(20 min)
Y por fin el último artículo de la serie IoT y Big Data. En el primero descubrimos algunos de los casos de uso de ambas tecnologías, y en el segundo artículo repasamos los tipos de analíticas de datos
En este tercer artículo tocaremos las arquitecturas para IoT y Big Data, y los sistemas existentes que hacen posible que todo esto funcione. En él vas a encontrar un buen número de referencias a tecnologías y sistemas que te pueden servir de referencia en tus proyectos.
Como en los otros dos artículos, continua siendo una traducción de paper
Analytics for the Internet of Things: A Survey
“Siow, E., Tiropanis, T., & Hall, W. (2018). Analytics for the Internet of Things: A Survey. Retrieved from http://arxiv.org/abs/1807.00971”
La figura que ves a continuación representa cómo el dato fluye desde la generación y recolección, pasa por la agregación e integración y termina en las aplicaciones analíticas. Los procesos de almacenamiento y computación no son realmente necesarios, pues la información podría fluir de una paso al siguiente de forma directa, aparecen porque en las implantaciones reales sí son fundamentales y a tener muy en cuenta, como vas a comprobar a lo largo de este artículo.
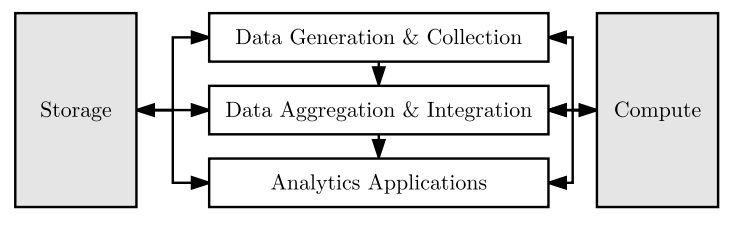
Veamos cada uno de estos procesos de una forma más detallada.
Contenido
Generación de datos: Sensores, etiquetas inteligentes, hardware, sistemas operativos y energía
La práctica totalidad de datos de IoT son adquiridos por sensores de todo tipo: ambientales, espaciales, biométricos, etc. Todos estos son dispositivos, digamos, tradicionales: elementos electrónicos con alguna parte que reacciona al entorno (humo, luz, temperatura, etc) y transmite la medida realizada a través de algún medio eléctrico hacia un otro dispositivo controlador.
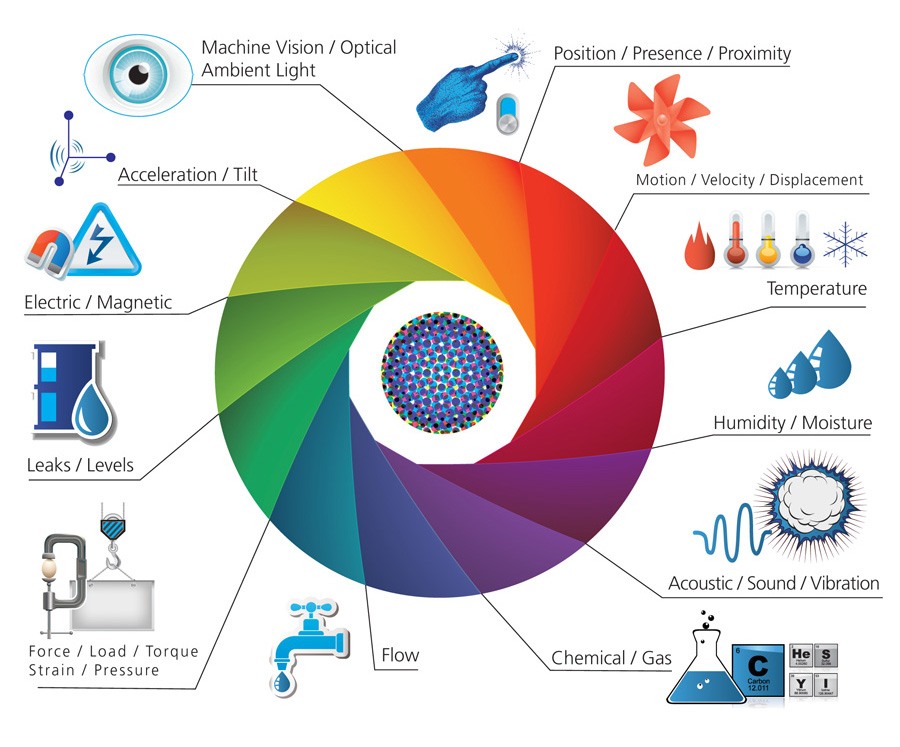
Pueden ser sensores tanto activos como pasivos. Por ejemplo las etiquetas QR o los códigos de barra pueden contener información, ambos son pasivos. También existen etiquetas activas como las iBeacon y las UriBeacon.
Con RFID tenemos un caso similar, pueden ser pasivas (las más habituales) o activas, que pueden transmitir en UHF (Ultra High Frequency), HF (High Frequency) o LF (Low Frequency).
Los sensores deben transmitir datos, pero cuando lo hacen de forma inalámbrica hay que tener muy en cuenta el consumo de energía. Complementando a todo los tipos de baterías que actualmente hay en el mercado, existen tecnologías que son capaces de extraer energía del entorno, sistemas de carga inalámbrica como uBeam y carga mediante el movimiento, como Ampy.
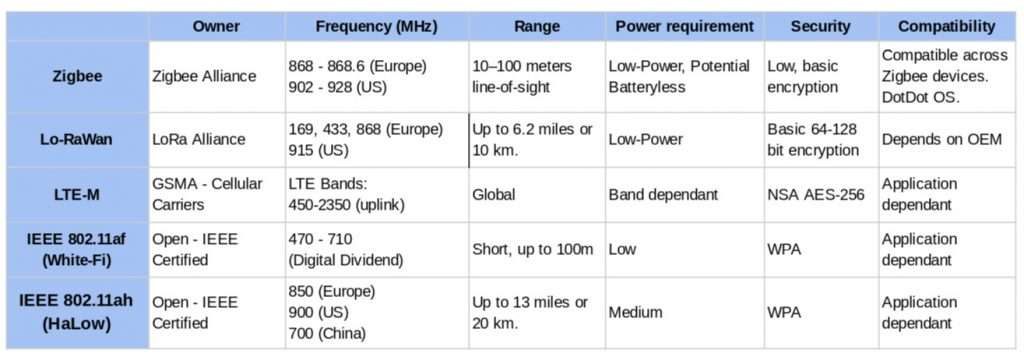
En la siguiente tabla puedes ver algunas de las tecnologías inalámbricas y las características de cada una, incluyendo los requerimientos de energía.
Recolección de datos: Descubrimiento, gestión, transmisión, contexto y Fog
Una de las áreas de mayor desarrollo y donde más trabajo se está realizando es la programación del middleware, el conjunto de software y aplicaciones que conecta los dispositivos, el almacenamiento, la computación y las redes como un todo.
Algunos estudios estiman que el mercado de middleware para IoTpasará de 6,9 billones (americanos) en 2018 a 19,5 billones en 2023.
El middleware de IoT debe proporcionar la siguientes funcionalidades:
- descubrimiento y gestión de recursos, en el proceso de adquisición de los datos
- gestión de datos y eventos, en el proceso de agregación de datos
- gestión de código de software, en el proceso de computación.
Tecnologías que permiten el auto descubrimiento de servicios y recursos a los dispositivos:
- Multicast DNS (mDNS)
- DNS service discovery (DNS-SD)
- Micro Plug and Play (µPnP)
- Simple Service Discovery Protocol (SSDP)
- Multicast COAP (MC-COAP)
Una vez descubiertos los servicios y los dispositivos, existen formas de gestionarlos, buscar y acceder a ellos, los llamados Thing Directories, por ejemplo:
En cuanto a la transmisión de datos, podemos hablar de:
- Transmisión del dispositivo al gateway, usando protocolos como Zigbee, LTE, GSM o LoRA. Puedes profundizar mucho más en estos y otros protocolos en este artículo: Towards An Internet Of Things Based Architectural Framework For Defence
- Transmisión en redes informática a partir del gateway, como TCP/IP, UDP, sin olvidar la encriptación y seguridad, como IPSec o el IEEE 1888.3 (Ubiquitous green community control network).
La computación basada en el contexto sigue siendo un área de investigación en IoT, que comprende la detección, compartición y agrupamiento de dispositivos según su contexto. El contexto puede verse como el lugar, tiempo, actividad e identidad en el momento de la adquisición del dato. Puedes ver un interesante artículo sobre este tema: Context-aware Sensor Search, Selection And Ranking Model For Internet Of Things Middleware
Pero sin duda alguna una de las infraestructuras que más suena últimamente para dar solución a la distribución de recursos y servicios en el IoT es el Fog Computing. De forma resumida podemos definir fog computing como una organización de elementos, recursos y servicios, que se posicionan entre los dispositivos y las aplicaciones en la nube, de manera que toda esa tecnología queda mucho más cerca de donde se producen los datos y por lo tanto más accesible. Puedes ver mucho más sobre fog computing en el artículo de este blog.
Agregación e integración de datos: interoperabilidad
La interoperabilidad es una de esas funcionalidades más perseguidas hoy en día por cualquier solución tecnológica. Es fundamental a la hora de hacer agregación e integración de los datos.
En este artículo (Cross-industry semantic interoperability) se describe una alianza entre varios fabricantes de la industria para ponerse de acuerdo en un modelo semántico de interoperabilidad: negocio, dispositivos, unidades de medida y API y servicios estándar.
Otros consorcios están trabajando en edificios y hogar, salud, transporte y logística y energía.
Linked Data promueve las buenas prácticas a la hora de publicar contenido en la web, de manera que se facilite el intercambio de información de manera semántica.
Schema.org también es un buen ejemplo de este tipo de iniciativas.
Arquitecturas de almacenamiento y computación
En esta sección prestaremos atención a qué tipo de arquitecturas, a alto nivel, necesitaremos para realizar el procesamiento y almacenamiento de toda la información IoT.
La arquitectura lambda está compuesta de una capa de velocidad, servicio y procesamiento por lotes. Consiste en procesar los datos en grandes lotes, mientras una capa de presentación compensa la baja latencia que podría afectar a la experiencia final del usuario, haciendo actualizaciones incrementales.
Existen diversos casos de uso en que se usa lambda: Netflix tiene una arquitectura similar y Yahoo lo ha implementado basándose en productos de Apache.
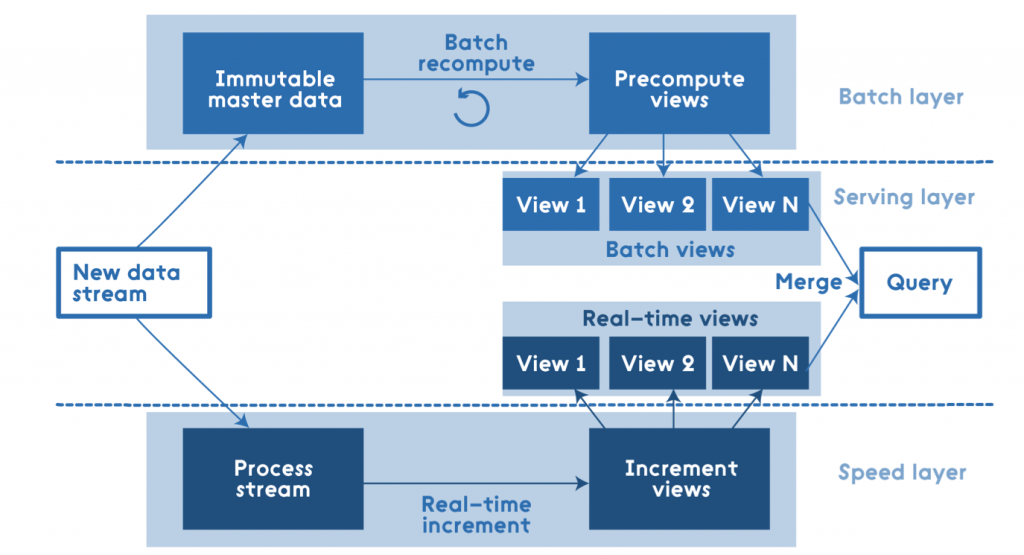
Hay propuesta de arquitectura basada en R y Hadoop donde se realizan procesamientos paralelos por lotes, para hacer minería de datos, y otras como MapR y Onix , hacen propuestas basadas también en lambda para realizar procesamiento de Big Data en tiempo real, o streaming.
A Scalable Machine Learning Online Service for Big Data Real-Time Analysis propone una arquitectura con la misma filosofía que lambda pero aplicada a aprendizaje automático y recomendaciones de ayuda a la toma de decisiones. Igualmente hace una división en las capas batch, serving y speed.
En este sitio https://dzone.com/articles/lambda-architecture-with-apache-spark puedes ver cómo funciona una arquitectura lambda basada en Apache Spark, Hadoop y otros elementos del ecosistema.
Existe algo de confusión a la hora de distinguir qué es Spark y qué es Hadoop. Puedes leer este interesante post donde resuelven las dudas. https://www.quora.com/Is-Spark-a-component-of-the-Hadoop-ecosystem
Como breve resumen, podemos afirmar que Spark es mucho mejor que la capa de procesamiento de Hadoop, por lo que este último termina siendo usado para el alojamiento y distribución de grandes conjuntos de datos, aspecto en el que tiene unas características realmente únicas.
Tecnologías de almacenamiento
En el punto anterior ya hemos visto alguna técnica de almacenamiento, basadas principalmente en arquitecturas centralizadas en la nube.
Pero tratemos ahora de ver cómo dar solución a sistemas de archivo que tienen que dar respuesta a la denominada computación a exascala (más de 10^18, un trillón en Europa, operaciones por segundo, 1 exaflops). En estos entornos se plantean tener millones de nodos y miles de millones de solicitudes concurrentes.
Para poder dar solución a esta inmensa cantidad de información es necesario gestionar los metadatos distribuidos, el particionado y los patrones de acceso a datos para mejorar la localización, la resiliencia y la alta disponibilidad.7
La siguiente lista de sistemas de archivos distribuidos tienen en común que los ficheros residen dentro de cada nodo, y luego son exportados a los clientes:
Si quieres profundizar en todos ellos, no te pierdas este artículo: Analysis of Six Distributed File Systems
Sin embargo, también existen sistemas distribuidos donde el acceso a los ficheros es también remoto, en servicios en la nube.
Una propuesta interesante, dentro del proyecto Smart Planet de IBM, es Gaian Database https://www.ibm.com/developerworks/community/groups/service/html/communityview?communityUuid=f6ce657b-f385-43b2-8350-458e6e4a344f.
Se trata de una base de datos distribuida, con organización automática, basada en principios biológicos y compuesta por nodos que contienen tanto datos estructurados como no estructurados. Está muy orientada hacia el mundo IoT y la analítica de los datos producidos en esos entornos.
Con Linked Data se construyeron métodos que fueron el comienzo de las consultas federadas (federated querying). Algunos motores de bases de datos que permiten las consultas federadas son:
- FEDX
- Splendid
- LHD
- DARQ
Otro elemento en el ecosistema del IoT es el llamado broker o gestor de mensajes. Son elementos de middleware, ubicados normalmente muy cerca del dispositivo, con capacidades de almacenamiento, reenvío y traducción de mensajería entre elementos heterogéneos y hacia y desde la nube. Algunos ejemplos son MQTT, Kafka y ZeroMQ (ØMQ).
Por si te ha parecido poco, existen bases de datos que aplican machine-learning para auto-optimizarse, haciendo una predicción de los momentos de más carga y clasificándolos, para optimizar el almacenamiento, la distribución de datos y el coste de las consultas. Un par de ejemplos son Peloton y Panoply.
Los MPP o sistemas masivos de procesamiento en paralelo están construidos siguiendo técnicas de shared-nothing: cada nodo es independiente y autónomo, evitando así que alguno sea un controlador y por lo tanto un punto de fallo. Algunos ejemplos de MPP son Greenplum, y Teradata .
Tecnologías de computación y aplicaciones de analítica IOT
Es bien sabido que la elasticidad de los sistemas que ofrecen los proveedores en la nube está muy bien valorada para entornos con altas necesidades de escalabilidad, como ocurre en las aplicaciones IoT.
Podemos dividir las tecnologías de computación en la nube en tres categorías:
- Virtualización
- Serverless
- Contenedores
La virtualización consiste en crear sistemas operativos completos, incluyendo la parte de virtualización de hardware, discos duros, etc. Es una tecnología muy extendida entre las empresas con instalaciones propias y en los servicios de alojamiento en la nube.
Las funciones serverless no es más que el desarrollo y ejecución de código en la nube sin estar contenido en un sistema operativo. La forma típica de llamar a estas funciones y recibir el resultado es mediante el uso de HTTP.
Los contenedores son una evolución de la virtualización, haciendo que cada imagen virtual ocupe mucho menos espacio, se inicie a mucha más velocidad y puedan ser gestionadas de forma automática con herramientas de orquestación. Es una técnica que cada vez está teniendo más aceptación en el diseño de plataformas totalmente elásticas.
En TSAaaS: Time Series Analytics as a Service on IoT puedes ver una propuesta de el uso de analítica de series de datos temporales como un servicio en la nube (TSAaaS), especialmente pensado para aplicaciones IoT.
También existen propuestas curiosas como IOT-StatisticDB: A General Statistical Database Cluster Mechanism for Big Data Analysis in the Internet of Things, donde se ha implementado en el mismo motor de la base de datos un conjunto de funciones estadísticas para ayudar a la analítica de datos IoT.
En PatRICIA — A Novel Programming Model for IoT Applications on Cloud Platforms puedes leer acerca de un sistema de desarrollo de alto nivel de aplicaciones IoT en la nube, que permite realizar con cierta rapidez el despliegue de aplicaciones para la gestión de dispositivos conectados.
Existen otras propuestas para realizar analíticas de datos en la nube, usando lenguajes como PMML (Predictive Model Markup Language).
Estos y otros muchos proyectos pueden ser clasificados en cuanto a la forma de ejecución y de distribución que tienen a la hora de desplegarse:
- Sistemas en memoria y en stream
- Modelos de programación en paralelo
- Modelos de grafos en paralelo
- Computación fog/edge
La comunicación de información entre los nodos de un sistema distribuido también es un asunto a tener muy en cuenta. RPC (llamada a procedimiento remoto), gRPC (es un RPC multiplexado) y Apache Thrift (un RPC asíncrono) son algunos ejemplos de ello.
«El modelo de actor» es un paradigma de la programación concurrente que permite poner en comunicación miles o millones de “objetos actor” o pequeñas colas de mensaje, usando para ello muy poca carga de CPU. Es un modelo creado en 1973, puedes leer algo más sobre el mismo aquí https://en.wikipedia.org/wiki/Actor_model
Para conseguir computación en tiempo real se pueden usar bases de datos en memoria, como H-Store y MemSQL, que permiten la ejecución de procedimientos almacenados de baja latencia y el acceso a consultas interactivas contra la base de datos.
Apache Spark posee una serie de herramientas de procesamiento de grandes cantidades de datos que merece que le prestes mucha atención, puedes leer una buena introducción aquí https://www.oreilly.com/library/view/learning-spark/9781449359034/ch01.html. Incluye procesamiento en memoria, en stream y en paralelo, conjuntos de datos distribuidos, optimizador de consultas SQL, procesamiento de eventos complejos (CEP), etc.
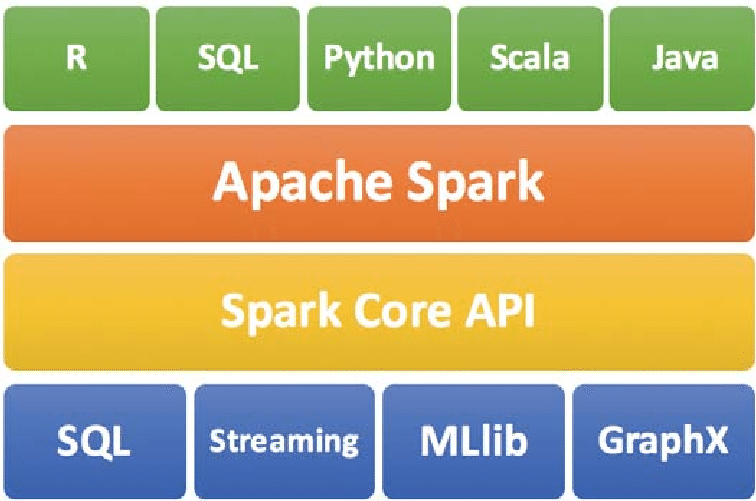
El procesamiento de datos en paralelo es la ejecución de nodos independientes sobre un mismo conjunto de datos, siendo sin duda alguna MapReduce la técnica que más se utiliza hoy en día, https://es.wikipedia.org/wiki/MapReduce. La implementación más conocida es Apache Hadoop Mapreduce.
Sobre Hadoop se implementan técnicas de clasificación de textos con Naive Bayes, motores de recomendaciones basados en top-K y clasificadores Random Forest. Sin embargo MapReduce no escala bien para algoritmos de grafos iterativos, debido a las escrituras en disco que conlleva. Para estos algoritmos se usan grafos paralelos, como GraphX (de Spark) o GraphLab.
Una curiosa propuesta para edge computing es la que realizan en ANGELS for Distributed Analytics In IoT, donde se usan los ciclos libres de CPU de dispositivos móviles con la ayuda de un organizador en la nube para la computación distribuida de datos IoT.
Si lo que buscamos es una organización real de computación y recursos en Fog, entonces estas propuestas pueden resultar más que interesantes:
- Ewya: An Interoperable Fog Computing Infrastructure with RDF Stream Processing,
- The Case for VM-Base Cloudlets in Mobile Computing
- Cisco IOX
Niveles de distribución de almacenamiento y computación
El Internet de las Cosas se puede definir como objetos físicos inteligentes e interconectados, con distintas capacidades de computación y almacenamiento.
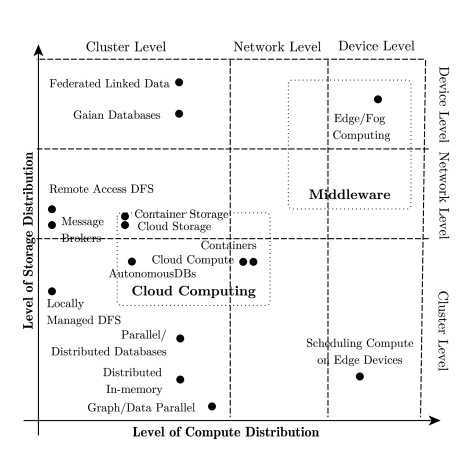
Las tareas de computación pueden realizarse en diferentes lugares dependiendo de cómo de lejos puedan separarse los datos de los objetos reales y las capacidades que estos tengan para procesar las tareas. Podemos ver tres niveles o lugares donde ejecutar la computación:
- A nivel de dispositivo, es decir, que las “cosas” tienen capacidad de cómputo y almacenamiento. Aquí podemos fijarnos en propuestas como Linked Data y Gaian Database, donde cada dispositivo almacena sus propios datos pero pueden ser accedidos desde fuera.
- A nivel de red, involucrando la comunicación con nodos de red, gateways, estaciones base, etc. En este nivel cae la gestión y uso de infraestructuras en la nube pública, puesto que implica la comunicación remota de los datos y el acceso a servicios de computación y almacenamiento remotos.
- A nivel de cluster, dentro de un conjunto de servidores interconectados ubicados dentro de una sala de servidores. Estos nodos tienen grandes capacidades de cálculo y almacenamiento y trabajan sobre los datos que tienen almacenados localmente. Algunos ejemplos son las bases de datos de procesamiento paralelo masivo, los Data Warehouse o las bases de datos distribuidas. A esta forma de funcionamiento también podríamos encajarla dentro de lo que se llama nube privada.
Y con esta sección finaliza el artículo, espero que te haya gustado y lo tengas de guía para futuras referencias.
Si te ha gustado y quieres seguir recibiendo las novedades del blog, no olvides suscribirte.
También puedes escribir en la entrada del blog con tus comentarios y sugerencias.
Nos vemos en el próximo !