(tiempo de lectura: 15 min)
Si has llegado a este blog seguramente ya has leído acerca de qué es el Internet de las cosas y, por lo tanto, no hace falta que repitamos todo desde el principio.
Una no llega a este sitio así como así sin haber navegado antes por algunos de los sitios más famosos sobre esta materia.

Sin embargo, no es tan sencillo encontrar artículos que expliquen qué es el Fog Computing y cómo está relacionado con el Internet de las cosas.
Y es el motivo principal que me lleva a hacer este post: explicarte de una manera práctica qué es Fog Computing y por qué va camino de convertirse en algo tan imprescindible.
Además, también verás cómo está relacionado con el Big Data, y cómo Big Data y Fog Computing van de la mano. Pero no profundizaremos casi nada en Big Data, para eso la tienes la serie de artículos sobre IoT y Big Data.
Si quieres tener una visión más teórica del asunto, te aconsejo que visites el artículo sobre Openfog.
Pero también te aconsejo que, después de leer este, repases el artículo sobre SmartFog, una arquitectura inspirada en el funcionamiento del cerebro humano, un buen ejemplo teórico sobre qué otras funciones puede llegar a tener una arquitectura de Fog Computing.
El artículo está vertebrado siguiendo la información que aparece en el paper
Perera, C., Qin, Y., Estrella, J. C., Reiff-Marganiec, S., & Vasilakos, A. V. (2017). Fog Computing for Sustainable Smart Cities: A Survey.
Retrieved from http://arxiv.org/abs/1703.07079
Y de él he tomado bastantes datos, y los he complementado y actualizado para tí con otras lecturas y fuentes.
Sin más, te agradezco de nuevo que te interese el tema. Vamos a meternos en harina
Contenido
¿Por qué necesitamos el Fog Computing?
El internet de las cosas promete ser una tecnología que va a cambiar el mundo, la forma en que vivimos y la forma en que se hacen y gestionan los negocios.
Su principal función es la de «sensorizar» el mundo físico, recoger esos datos, analizarlos y enviar de vuelta una respuesta automatizada, dirigida bien a la parte de negocio o de vuelta al mundo físico.
Esta forma de funcionamiento nos permitirá tener un control tan detallado como queramos del proceso que queramos medir pudiendo, además, actuar sobre el mismo.
Los servicios, los productos, la alimentación, la salud, van a poder ser observados y gestionados de una forma muy atómica e individualizada para cada consumidor.
Para llegar a este resultado hay una serie de dificultades que debemos cubrir de antemano. Una de ellas, ahora mismo de las más importantes, es cómo hacer que todos esos datos lleguen a la nube y se analicen en tiempo real, de tal forma que la respuesta que enviamos de vuelta sea lo más rápida posible.
Este asunto es más importante cuanto más crítico es el tiempo de respuesta o cuanto más crítica es la infraestructura que pretendemos manejar.
Por ejemplo, un sistema IoT aplicado a la gestión de emergencias y desastres naturales puede no estar operativo en los momentos clave si depende exclusivamente de una sola infraestructura en la nube.
¿Por qué fog computing viene a solucionar todo esto?
Básicamente porque lleva todas las técnicas de alta disponibilidad, resiliencia, seguridad y flexibilidad de la nube a un entorno más cercano a donde se encuentran los objetos conectados a Internet, o Internet Connected Objects (ICO) . Fog computing está basado en una red de nodos auto coordinados entre sí para dar respuesta a las necesidades de todas los ICO a su alcance y hacer de puente hacia las plataformas en la nube.
Sin el desarrollo e implementación del fog computing el IoT no va a poder llegar a las cotas de despliegue que se está pensando a día de hoy, y que tantos vídeos está inspirando, donde vemos un derroche de imaginación dignos de las mejores películas de ciencia ficción.
Los fabricantes tanto de software como de hardware están creando ya sus divisiones dedicadas al IoT, y podrás ver que muchos de ellos ya tienen despliegues con nodos «edge». Por ejemplo, la plataforma IoT Losant es capaz de desplegar nodos del tipo edge y hacerles ejecutar un flujo de instrucciones programadas previamente en su editor en la nube.
Si bien podemos considerarlo un paso en este sentido, no es realmente el tipo de infraestructura que quiero contarte hoy.
Por eso, empecemos por las …..
Características del Fog Computing
Podríamos usar una frase como lema que seguir en diseño de cualquier arquitectura de fog computing:
Hazlo en el nodo edge
Es decir, hacer en los nodos finales todas las operaciones posibles, intentando minimizar las operaciones en la nube, que ya de por sí serán muchísimas.
Una red de nodos edge debería tener dos partes muy diferenciadas:
- El plano de control, usado para la administración de la red de nodos, monitorización, actualizaciones, etc
- El plano de datos, justo para hacer fluir datos hacia la nube, hacia los ICO y desde todos ellos.
Sin embargo, por muchas similitudes que existan, el fog computing se diferencia del cloud en estos puntos:
- Se almacenan los datos en los nodos edge de forma distribuida, en vez de enviarlos a un sitio central en la nube
- Se usan redes locales de distinta índole, liberando a los backbones de tráfico y diversificando las comunicaciones
- Se realiza un procesamiento distribuido de los datos en el edge, en vez de tener un gran centro de computación en la nube.
- Los dispositivos edge son auto gestionados, manejados y controlados, sin necesidad de un control único ubicado en la nube. Obviamente esto requiere un trabajo previo de diseño y programación.
En el siguiente diagrama de categorías de dispositivos basándonos en su capacidad de cómputo, los dispositivos edge van desde la categoría 1 a la 4.

El hecho de que los recursos, el análisis de los datos y la densidad de nodos se lleve tan cerca de los dispositivos finales hace que la experiencia del usuario se vea muy mejorada, debido a las bajas latencias, alta disponibilidad y resiliencia ante fallos. De esta forma será posible tener experiencias en tiempo real para las aplicaciones de realidad aumentada, realidad virtual, navegación, etc.
Otro de los aspectos que el fog computing viene a mejorar es la optimización de la captación de datos para procesamientos Big Data. Añadiendo inteligencia a los nodos edge es posible hacer una sensorización adecuada y consciente del contexto, de tal manera que solo se suban datos a la nube que sean significativos o importantes.
Una de las derivadas de esta forma de procesamiento de datos son las técnicas de sincronizacíon de información, donde los esquemas pull/push y suscriptor/publicador son los más habituales.
La resiliencia a las que hacía referencia antes va permitir que toda la red de nodos fog continue funcionando con casi la totalidad de prestaciones cuando existan problemas de comunicaciones con la parte de la nube, permitiendo el desarrollo de aplicaciones de gestión de desastres naturales, protección y seguridad de la población, etc.
Para este tipo de aplicaciones será fundamental que los nodos edge adquieran conocimiento o «consciencia» de su entorno, mediante la colaboración entre ellos, para permitir un funcionamiento autónomo en los momentos donde un orquestador más arriba mantenga la lógica de funcionamiento.
Sin embargo, el fog computing también tiene sus propias limitaciones, entre las más importantes están:
- La capacidad limitada de procesamiento dentro de los nodos edge y los ICO. Aunque poco a poco en el mercado empiezan a aparecer dispositivos más potentes y de menor tamaño. Si quieres ir viendo alguno, échale un vistazo al Omega2 Plus, del fabricante Onion. Es un micro controlador, del tamaño de los archiconocidos ESP8266 y ESP32, pero con capacidad para ejecutar un sistema operativo Linux completo.
- El consumo de energía: este aspecto siempre jugará en nuestra contra, si queremos mayor procesamiento necesitaremos más energía, si queremos que la energía nos dure más, tendremos que sacrificar el procesamiento y las comunicaciones. La solución está en recopilar energía del entorno, tanta como sea posible: energía solar y eólica, mediante vibraciones, desde las onda electromagnéticas, etc. Evidentemente cuando más optimizado esté el uso de energía, menos nos afectará el problema.
- La seguridad: se abre todo un mundo nuevo a la hora de proteger un «dispositivo» distribuido en cientos de nodos, sin una frontera bien definida, con multitud de formas de comunicación y con una composición y funcionamiento cambiante. Además en este campo, debemos agregar la privacidad de los datos, que daría para una charla completa. La seguridad y la privacidad de los datos son dos frenos importantes, tanto por su complejidad técnica como por sus consecuencias legales e impedimentos normativos. Las últimas tendencias hablan de la seguridad apoyada por técnicas de Inteligencia Artificial (AI) y Machine Learning (ML), tal como te explicaba en este post.
Nuevamente me remito al artículo sobre Openfog si quieres mucha más profundidad en cada una de las características del Fog.
Casos de uso del Fog Computing
A pesar de que en otros artículos has podido leer sobre los casos de uso del IoT, a continuación verás una breve referencia a casos específicos para fog computing.
Agricultura inteligente
Existen algunas propuestas, como el proyecto Phenonet,(actualmente parece abandonado), para la monitorización de las condiciones del campo y del crecimiento de las plantas. Este proyecto plantea el despliegue de nodos de dos tipos, sensores y gateways, si bien estas funciones podrían estar simultáneamente en algunos de ellos. También propone la recolección de estos datos mediante globos aerostáticos y vehículos móviles en tierra, de tal manera que se eliminen las comunicaciones inalámbricas de larga distancia.
Estas propuesta que, a priori, podría parecer algo rocambolesca, saca a colación los métodos de captación de datos usando la menor energía posible en las situaciones en que no es necesario un acceso continuo a los datos.
Además el sistema propuesto por Phenonet habla de una recolección y frecuencia de lectura de datos variable, en función de las condiciones climatológicas y las predicciones.
No se requiere la misma cantidad de datos cuando el clima es estable y las predicciones para los próximos días no varía mucho, que cuando existen riesgos de helada, o cuando hay una meteorología variable.
En el mercado existen algunas propuestas que también proponen redes de nodos, pero con comunicaciones inalámbricas, siendo algunos de ellos gateways de comunicaciones hacia los cuales fluyen los datos del resto de sensores. En España tenemos a la empresa Libelium, sin duda uno de los mejores ejemplos que apuestan por este tipo de tecnologías,
Transporte público
Imagina que quieres usar los autobuses urbanos para colocarles un kit de sensores ambientales y que mientras recorren la ciudad vayan recopilando datos sobre la contaminación, los gases, ruido ambiente, etc.
Dado que en este ejemplo no es necesario tener los datos en tiempo real, nos bastaría con tener nodos gateway en algunas paradas concretas para que el autobús, al detenerse en la misma, transfiera los datos a la nube.
Pero además, nos encargan que en los días de lluvia sí queremos los datos en tiempo real y, por lo tanto, hay dotar a los autobuses con comunicaciones 3G, por ejemplo.
Este es un caso muy sencillo donde podemos ver cómo los kit de sensores de los autobuses se comportan de forma autónoma, eligiendo de qué forma van a transferir los datos y teniendo como apoyo una red de nodos fijos para el envío de datos que no son necesarios en tiempo real.
Como ves se tratan de nodos que son capaces de elegir y funcionar con distintas tecnologías y frecuencia de comunicaciones según las condiciones del entorno. También podrían enviar alertas inmediatas si ven condiciones de contaminación o de ruido excesivas, informando a las autoridades de una forma más directa.
Gestión de residuos
La recogida y tratamiento de los residuos urbanos sin duda es uno de los típicos ejemplos que se sugieren para el uso del IoT.
Sin entrar en demasiado detalle, podemos simplificar todo el sistema atendiendo a los participantes del mismo:
- Autoridades locales que quieren dar un servicio eficiente y lo más económico posible, cumpliendo las condiciones del contrato establecido.
- Las empresas que realizan la recogida y tratamiento posterior que quieren automatizar y mejorar sus procesos lo más posible.
- Las autoridades sanitarias que quieren estar completamente seguras de cómo se realiza todo el tratamiento de productos de deshecho y basuras.
Todas estas partes quieren estar seguras que las otras están realizando las tareas con la máxima calidad y cumpliendo las normativas y contratos, y al mismo tiempo desean que sus propios procesos estén optimizados.
La idea típica, y que aquí te voy a ampliar un poco, es la colocación de sensores en los contenedores y lugares de recogida de residuos.
Estos sensores pueden transmitir los datos de forma inalámbrica o bien esperar a que pase algún camión de transporte que se lo solicite.
También podrían ser «testigos» de otro tipo de eventos, como por ejemplo cómo de a menudo se vacía y recolecta su contenido o a qué ritmo se llena.
En este sentido puede que no sea necesario siquiera que se envíen datos, especialmente si los mismos no aportan una información extra. Por ejemplo, si un contenedor tiene una tendencia a llenarse a un ritmo X, no es necesario que se envíe los datos si está cumpliendo ese perfil.
Sin embargo, sí se enviarán en caso de que el ritmo de uso el contenedor varíe.
De nuevo los propios contenedores decidirían en cierta medida su forma de funcionamiento, enviando los datos solamente cuando es realmente necesario y usando para ello comunicaciones inalámbricas, un camión de transporte, que en este caso haría las veces de nodo del sistema fog, o cualquier medio que se ponga a su alcance y haya sido previamente preparado.
Gestión del agua
De nuevo tenemos uno de los casos de éxito que está teniendo el IoT hoy en día.
La gestión del agua y de todo su ciclo en una sociedad cobra cada día más importancia, desde su canalización en los puntos de recogida, su tratamiento, la distribución, las fugas, la depuración posterior, incluso el destino final hacia donde se dirige.
En cada uno de esos aspectos la tecnología está jugando hoy en día un papel fundamental. Toda una red de sensores es necesaria para monitorizar cada uno de estos procesos, con la mayor precisión posible y con el mayor control del que seamos capaces.
Tener una red de nodos inteligentes desplegados por la ciudad hace que los dispositivos finales de monitorización sean más sencillos y más fáciles de desplegar y colocar permitiendo, por lo tanto, un mayor número de ellos. Además, facilitaría el traslado de los mismos si fuera necesario.
La seguridad en el suministro de agua: calidad, salubridad, cantidad, etc es otro de los aspectos fundamentales, donde la seguridad de la población podría verse comprometida.
Redes eléctricas inteligentes o smart grids
El balanceo de las redes eléctricas de forma automática para asegurar el suministro a los ciudadanos empieza a ser cada día más complicado, especialmente con la proliferación de las energías renovables y la posibilidad de que introduzcan energía en casi cualquier punto de la red.
En el artículo sobre smart-grids se habla del futuro de la electricidad y cómo podía convertirse en un mercado en tiempo real de la energía, donde los prosumers pudieran comerciar con su exceso de producción.
Además de esta posibilidad, las redes deben seguir siendo gestionadas de una forma segura. Los contadores inteligentes que se mencionan en el artículo forman una red de fog computing con capacidades de decisión y colaboración con otros elementos de la red.
Quizás a todo esto le falte un empuje en el tema de coordinación de los dispositivos, y la decisión del cambio de funcionamiento según las condiciones circundantes, pero sin lugar a dudas es un buen ejemplo de aplicación del IoT y fog computing.
El caso más reciente (en el momento de escribir este artículo) de implantación piloto de este tipo de técnicas lo tenemos en Sevilla, en la Isla de la Cartuja.
Comercio y disponibilidad de artículos
Si entramos en el mundo del bienestar y las comodidades de las ciudades podemos ver cómo una de ellas es la posibilidad de encontrar la más variada clase de artículos en las numerosas tiendas que existen. Pero, ¿cómo llegan estos artículos al estante? ¿Es un proceso depurado y optimizado? ¿Cómo podemos hacer que lo sea? ¿Podemos predecir qué artículos harán falta en pocos días y si el proveedor llegará a tiempo para entregarlos?
De nuevo el Internet de las cosas se alía con nosotros para darnos la solución. El smart-retail es la técnica de monitorización del comportamiento de los clientes, de la disponibilidad de los productos en el estante, en el almacén e incluso la disponibilidad y tiempo de entrega de los proveedores.
Bien es sabido que las grandes superficies vienen aplicando este tipo de técnicas desde hace bastantes años pero, ¿cómo podríamos hacer que esta tecnología estuviera disponible en las tiendas de barrio?
Se podría desplegar una red de nodos fog en las zonas comerciales y que en las tiendas solo hiciera falta los dispositivos más sencillos y con comunicaciones más económicas. De esta forma casi cualquiera podría aplicar técnicas de gestión de artículos tal como hacen las grandes empresas.
Una red de nodos fog computing junto con una aplicación apropiada en la nube serían una buena solución, no crees?

Funcionamiento del Fog Computing
Una vez te he abierto el «apetito» de conocer más sobre el fog computing, voy a presentarte qué características debe tener y como debe funcionar para que los ejemplos anteriores, y muchos otros que seguro que se te han ocurrido, puedan llevarse a cabo.
Dispositivos edge
El componente principal y más novedoso en todo esto del fog computing son precisamente los dispositivos «edge», es decir, aquellos que están en el borde, más cerca del usuario, los dipositivos finales.
Dado que son estos nodos edge los que van a ser utilizados de una forma distinta, dándoles funcionalidades que hasta ahora no tenían, conviene hacer una clasificación atendiendo a los recursos principales que van a necesitar: memoria y proceso, consumo de batería y capacidades de comunicación.
En las siguientes tablas podemos ver esta clasificación, atendiendo a la capacidad de almacenamiento, a la energía que consume y a sus necesidades de comunicación, siguiendo la recomendación de la IETF:
| Name | data size (e.g., RAM) | code size (e.g., Flash) |
|---|---|---|
| Class 0, C0 | « 10 KiB | « 100 KiB |
| Class 1, C1 | ~ 10 KiB | ~ 100 KiB |
| Class 2, C2 | ~ 50 KiB | ~ 250 KiB |
| Name | Type of energy limitation | Example Power Source |
|---|---|---|
| E0 | Event energy-limited | Event-based harvesting |
| E1 | Period energy-limited | Battery that is periodically recharged or replaced |
| E2 | Lifetime energy-limited | Non-replaceable primary battery |
| E3 | No direct quantitative limitations to available energy | Mains powered |
| Name | Strategy | Ability to communicate |
|---|---|---|
| S0 | Always-off | Re-attach when required |
| S1 | Low-power | Appears connected, perhaps with high latency |
| S2 | Always-on | Always connected |
El procesamiento de datos que se realiza en estos dispositivos se llama analitica en el borde, o edge analytics. Los dispositivos de este estilo podríamos diferenciarlos además dependiendo de si son capaces de ejecutar un sistema operativo (los llamaríamos gateways) o no (los llamaríamos ICOs, Internet connected object).
Descubrimiento dinámico
El descubrimiento dinámico es la capacidad que tiene un objeto conectado (ICO) para encontrar a su alrededor las infraestructuras y elementos necesarios para poder funcionar y cumplir su misión. Si el entorno es cambiante, el ICO también debe ser capaz de cambiar su «percepción» o los objetos que descubre.
El descubrimiento dinámico de los grandes retos del IoT hoy en día, debido sobre todo a su heterogeneidad, las implicaciones en la seguridad y la naturaleza cambiante de los entornos físicos.
Por ejemplo, si una determinada aplicación IoT necesita conocer la temperatura o cualquier otro dato de un cierto lugar o maquinaria, podría hacerlo usando distintos sensores y dispositivos a su alrededor. Tendría que averiguar cuál de ellos le interesa, qué tipo de dato entrega, con qué error, e incluso cuándo debe consultar el dato y con qué frecuencia.
Si además sumamos que en IoT uno de los objetivos es poder actuar sobre el entorno, todo se complica más.
Existen muchos tipos de actuadores: eléctricos, mecánicos, hidráulicos, neumáticos, micro-electro-mecánicos, etc. Y según cómo actúe en el entorno podemos dividirlos en lineales y no lineales
La configuración automática de nano sensores se vuelve primordial, especialmente cuando el número de estos se multiplica y el tamaño de los mismos disminuye día a día hasta escalas insospechadas hace tan solo unos años.
La nanotecnología está consiguiendo hoy día que se puedan poner a circular sensores dentro de nuestro cuerpo, informando a unidades externas sobre los datos que necesitan recopilar.
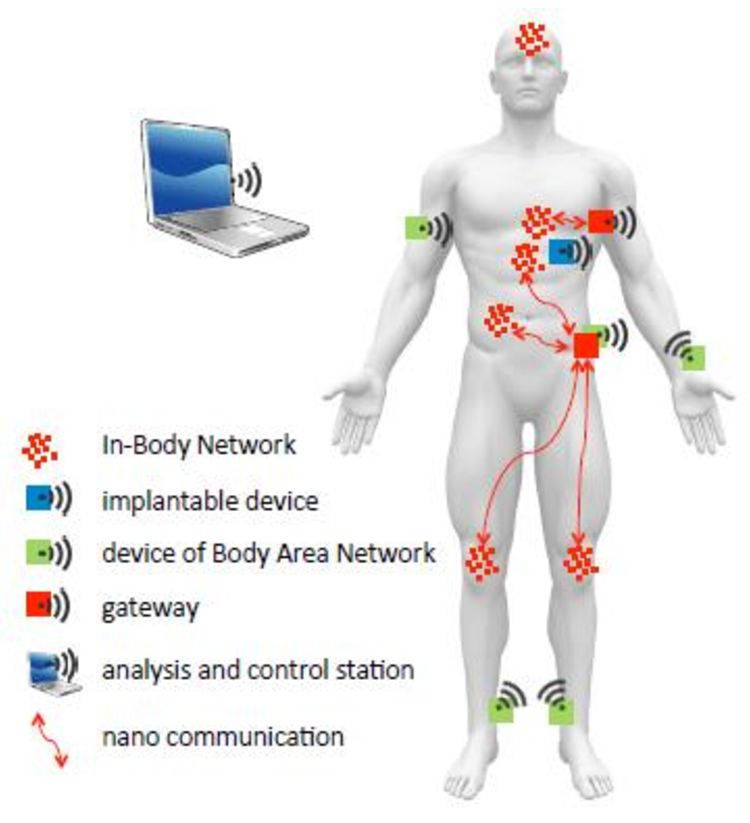
Lakshmi, Dr. I.. “Interfacing In-Body Nano Correspondence with Form Region Networks : Tests and Chances of the Web for Nano Things.” (2017).
Estos mismos nanosensores podrían desplegarse en los hogares, oficinas y en ciudades, con el fin de detectar el avance de ciertas enfermedades e infecciones. Apoyados en una red de fog computing podrían ser de gran utilidad a las autoridades sanitarias.
Un último apunte, el autodescubrimiento puede ser bidireccional: los ICO descubriendo qué gateways hay a su alcance y los gateways encontrando qué ICOs le pueden ser de utilidad.
Configuración y gestión dinámica
Profundizando más en la configuración dinámica, debemos observar cómo es la cadena de comunicación entre un ICO y la nube.
El ICO se conecta a un gateway, este recopila los datos relativos a cómo funciona ese ICO, qué protocolos usa, etc y los envía a la nube. A este proceso se le llama «registro». De la misma forma la nube debe saber qué ICOs son alcanzables por cada gateway y qué instrucciones pueden aceptar para actuar sobre ellos.
El papel fundamental de los gateways es precisamente descubrir cómo funcionan y qué protocolos soporta cada ICO, para ofrecerlos a la aplicación en la nube.
Con el crecimiento del número de objetos conectados parece más que claro que este proceso debe ser automático o al menos los más automático posible.
En los últimos años han aparecido distintas propuestas para estandarizar la forma en que se describen los objetos conectados a internet, facilitando así cómo describirlos y la interoperabilidad de aplicaciones IoT. Algunas de estas propuestas son:
- Sensor Ontologies: Sensor ontologies [Compton et al. 2009]
- Transducer Electronic Data Sheet (TEDS) [IEEE Instrumentation and Mea- surement Society 2007]
- SensorML, sensor markup language
Y algunos entornos de programación y frameworks ya están avanzando en estos aspectos:
Además de cómo un ICO puede describirse a sí mismo y cómo puede comunicarse, debe especificar qué métodos usa para enviar los datos y con qué frecuencia va a hacerlo.
- Método pull. Son los gateways quienes solicitan el dato al ICO, incluso la propia aplicación en la nube puede solicitar el dato para leer.
- Método push. El ICO envía el dato al gateway directamente. De este método se derivan los archiconocidos sistemas suscriptor/publicador.
- Envío instantáneo, o por superacíon de umbral. Permite tanto pull como push, y solo se envía o solicita el dato al ocurrir un evento, producido en el ICO o en el gateway
- Envío periódico o a intervalos. Es una derivada del envío por eventos, solo que en este caso el evento lo dispara el transcurrir del tiempo. Un dato determinado se envía cada X tiempo, es lo que se llama un muestreo.
Así que estas dos variables, método de acceso al dato y frecuencia, son fundamentales y afectan tanto a cómo se comportará la aplicación en la nube como al gasto de energía de ICOs y gateways. Dado que los ICOs no tiene «consciencia» de su entorno no pueden proponer cambios en estas dos variables y, hasta ahora, era una responsabilidad que debía caer en la aplicación en la nube.
Sin embargo, Fog Computing propone que sean los gateways quienes realicen estos ajustes finos, pues ellos sí que están en contacto directo con el entorno. Podrian generar una mini programación, que transmita a sus ICOs más cercanos y que las varíe en función de las necesidades de la nube y de los datos adquiridos.
Protocolos de comunicaciones
Como ya sabes, existen en la actualidad un buen puñado de protocolos inalámbricos que nos sirven para comunicar los ICOs con los gateways y estos con la nube. Ninguno de ellos es claramente mejor que los otros, cada uno tiene sus puntos fuertes y sus problemas, y por lo tanto deben ser utilizados y elegidos donde convengan.
Hay varios factores a tener en cuenta, pero algunos de los más importante son el ancho de banda, el radio de alcance de la comunicación y la energía que se consume.
La siguiente tabla te resume los principales protocolos y cada una de estas variables, junto a algunas otras. Entenderás que decantarse por uno u otro no es tarea fácil.
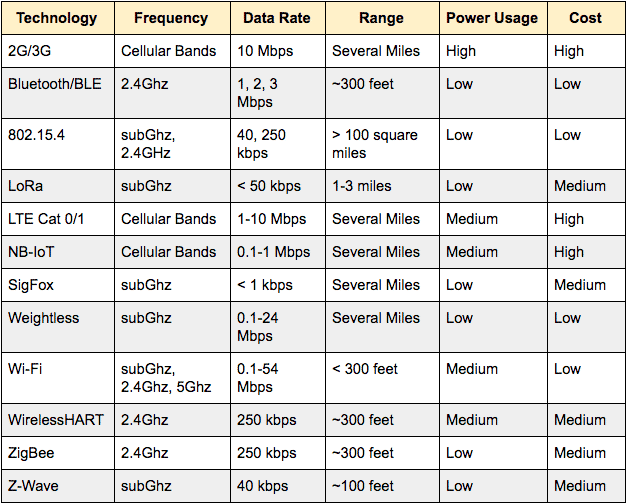
De todas formas, como te comentaba antes, cada vez salen al mercado microcontroladores con más capacidad de cómputo y de memoria, así que en breve podremos elegir el protocolo solo por sus características físicas, olvidándonos del resto de variables.
El siguiente diagrama muestra qué posición ocupa cada protocolo IoT (tanto de comunicaciones como de aplicación) dentro del estándar OSI, me parece uno de los más aclaratorios:
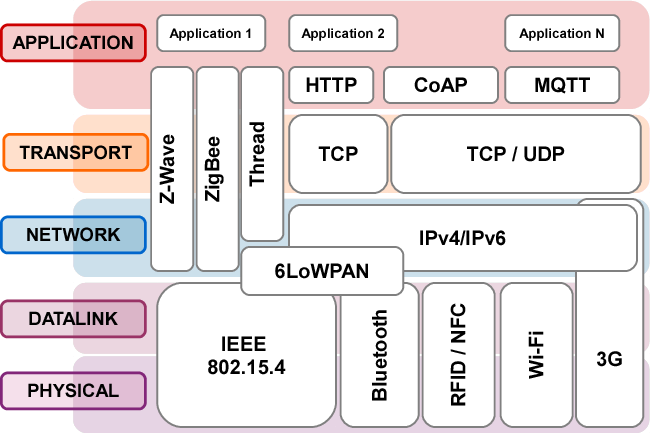
Protocolos de aplicación
Sin embargo es en el protocolo de la aplicación donde no hay tanto para elegir, y varios de los proyectos que hace algunos años parecían que repuntaban se han ido quedando atrás.
Quizás uno de los motivos que nos llevan a tener un importante grupo de protocolos y que ninguno de ellos sea definitivo es el tipo y número de funcionalidades que se buscan. Según [Buyya and Vahid Dastjerdi 2016], estas serían las principales necesidades a cubrir:
- Broadcast (difusión) de información de uno a muchos
- Recibir eventos independientemente de donde se producen
- Enviar pequeños paquetes de datos en grandes cantidades
- Enviar información usando redes no fiables (en cuanto a la entrega del paquete)
- Gran sensibilidad ante el envío de grandes volúmenes de información y su coste
- Sensibilidad ante la cantidad de energía consumida, sobre todo para dispositivos alimentados por baterías.
- Gran capacidad de respuesta, casi en tiempo real en algunos casos
- Seguridad y privacidad
- Escalabilidad
Todas estas características son deseables en las comunicaciones de dispositivo a dispositivo (D2D), de dispositivo a servidor (D2S) y de servidor a servidor (S2S).
Los principales protocolos usados por las aplicaciones en IoT hoy en día son:
- HTTP: HyperText Transfer Protocol. Es del tipo D2S y, comparado con el resto, está menos optimizado para el uso en el Internet de las Cosas. Sin embargo, está más que probado y es posible implementarlo en casi cualquier dispositivo.
- XMPP: Extensible Messaging and Presence Protocol. Se trata de un estándar abierto aprobado por la IETF pensado para comunicaciones en tiempo real, usando sobre todo datos en formato XML. Añade a la comunicación bastante carga en cabeceras y datos de control
- MQTT: Message Queue Telemetry Transport. Es un protocolo ideado por IBM para la monitorización de infraestructuras pretroliferas desde satélites. Es muy ligero en cuanto al formato de datos, siguiendo un esquema de publicador/suscriptor. No está pensado para comunicaciones en tiempo real o que necesiten altas velocidades de respuesta. Las librerías de programación está optimizadas y es posible embeberlas en cualquier dispositivo. Hoy en día es un estándar bastante maduro.
- CoAP: Constrained Application Protocol. Es un protocolo D2D que funciona exclusivamente sobre redes IPv6 (6LoWPANs). A pesar de ser un protocolo algo más pesado que MQTT, mejora a este en cuanto a funcionalidades implementadas en el mismo, como por ejemplo el autodescubrimiento de dispositivos y una seguridad mejorada.
- AMQP: Advanced Message Queuing Protocol. Muy adecuado para el plano de control del IoT, puesto que está centrado en que ningún mensaje se pierda en el camino, permitiendo comunicaciones uno a uno y en modo publicador/suscriptor. Implementa un sistema de transacciones, o cual es toda una ventaja da seguridad al control de dispositivos.
Si quieres profundizar algo más en todos estos protocolos y las diferencias que hay entre cada uno, te consejo el artículo All About Messaging Protocols
Mobilidad
No podemos dar por hecho que los gateways y los ICOs estarán siempre conectados y en un sitio fijos. Si se optimizan las comunicaciones, la cantidad de información enviada y la energía usada, se puede incrementar el número de ICOs gestionados por cada gateway. Incluso podemos plantearnos gateways que se muevan por un área extensa con cierta densidad de ICOs. En estos entornos el autodescubrimiento adquiere una importancia especial, y debe ser muy eficiente y efectivo.
Existen multitud de escenarios donde podemos aplicar este tipo de técnicas, pero sin duda uno de los que más puedes encontrar es en la gestión de desastres naturales, donde el despliegue de drones puede ser la clave para zonas devastadas por algún accidente o inclemencia. Si además le añadimos una red de nodos edge que son capaces de seguir funcionando cuando todo a su alrededor está casi destruido, podemos tener un despliegue técnico muy útil para los equipos de rescates y para la población afectada.
Tratamiento de datos
Hemos hablado de las capacidades de comunicación, del consumo de energía o de cómo se puede mover un gateway en busca de los ICOs. Pero la piedra angular del Fog Computing, la gran aportación que hace, es la capacidad de transformar los datos en información en una capa muy cercana a los objetos, sin tener que llegar a la nube.
Esto se puede hacer porque los gateways estarán preparados para realizar «analítica en el borde» (edge analytics) con los pocos datos que tenga históricos o mediante algoritmos que lleguen preparados desde la nube. En muchas ocasiones se tomarán las decisiones en el propio edge y no hará falta acudir a la nube para nada, y probablemente el dato se elimine una vez haya sido procesado y usado.
La potencia que se consigue con la «ciencia de los datos», término muy de moda estos días, se basa precisamente en la analítica aplicada a un gran número de datos históricos. Aún así, no significa que haya de hacerse en cada ocasión, y hay muchas situaciones donde no es necesario esa potencia ni tener tantos datos disponibles.
La calidad del dato también debe tenerse en cuenta, y la fiabilidad de la fuente. No es igual el dato que se obtiene de la temperatura de un sensor super preciso que el conteo de personas que pasan cerca de una antena mediante la detección de su móviles por Bluetooth. Son dos tipos de datos totalmente distintos, con errores distintos y donde se ha de tener en cuenta las conclusiones y operaciones que se harán con los mismos.
Descubrimiento del entorno y del contexto
Pero, ¿cómo aplicar la técnica adecuada de recolección de datos? ¿Cómo saber si los datos recibidos tienen sentido o cómo de precisos son? ¿Cómo detectar que un sensor ha dado un dato incorrecto?
Los gateways deben estar diseñados para «descubrir su entorno» y entender «qué está ocurriendo a su alrededor»
Si se detecta que un sensor ha entregado un dato anómalo se podría empezar a consultarlo de una manera más insistente y comparar esos datos sospechoso con toda la serie de datos anterior y, en función de este análisis, decidir qué hacer con el sensor: si anularlo y notificar la situación, si marcarlo como sospechoso o simplemente es que ha ocurrido un fallo momentáneo de la medida. También podría consultar a otros gateways y cruzar datos con ellos para averiguar qué ocurre en el entorno.
El objetivo es filtrar los datos incorrecto o poco precisos lo antes posible, aplicando técnicas de sensorización balanceada entre gateways y con patrones de lectura que pueden cambiar según la información recibida.
Anotaciones semánticas
La anotación semántica de los datos es una de esas técnicas que prometen hacer el desarrollo de aplicaciones «inteligentes» más ágil pero que no termina de despegar. Se trata básicamente de tener un diccionario de objetos, características, funciones, etc que compañen al dato y lo caractericen. El objetivo principal es facilitar la publicación de datos y la interoperabilidad entre aplicaciones de distinta índole.
Esta no es una idea nueva, ni mucho menos. Ocurre igual que con otras áreas de las tecnologías de la información, como el Machine Learning (ML) y la Inteligencia Artificial (IA), que fueron ideadas hace décadas pero no es hasta ahora cuando realmente merece la pena abordarlas, gracias a las capacidades de computación, comunicaciones y almacenamientos actuales.
Es un tema muy interesante, de esa piezas que se harán imprescindibles para dotar de «inteligencia» y coordinación a un sistema completo IoT.
Si quieres leer un artículo reciente sobre el tema, te aconsejo este: Al-Osta, M., Ahmed, B., & Abdelouahed, G. (2017). A Lightweight Semantic Web-based Approach for Data Annotation on IoT Gateways. Procedia Computer Science, 113, 186–193. https://doi.org/10.1016/J.PROCS.2017.08.339
Analítica de datos
Sin embargo no es fácil dotar a nodos finales de grandes capacidades de analítica de datos, a pesar de que cada día son dispositivos más potentes, es complicado que puedan llegar a hacer todo lo que se hace en la nube, pues es allí donde se dispone de mayores recursos de computación.
La idea es que en los nodos finales se deplieguen ciertas capacidades básicas de analítica, de forma modular y dinámica. De esta manera a cada nodo se le proveerá de las funciones que realmente necesita: medias, series temporales, detección de outliers, etc.
Por lo tanto habrá que desarrollar herramientas que permitan realizar este tipo de «plantillas» o módulos, para poder ser desplegados posteriormente y aplicados a los datos finales.
Las técnicas de reducción de dimensionalidad también son interesantes en el fog computing, pues serían responsables de disminuir drásticamente la cantidad de información a subir en la nube.
Dadas las limitadas capacidades de almacenamiento, la analítica de datos en streaming deber ser uno de las técnicas a desarrollar. Es muy común ver sistemas que analizan datos ya almacenados, millones de registros en un solo conjunto de datos, pero esta situación está lejos de ser posible en los nodos edge, que deben analizar los datos tal como llegan.
Seguridad y privacidad
Y aquí llega, como se suele decir, la madre del cordero. Sin duda uno de los aspectos qué más reticencia produce y qué más podria estar frenando el avance del IoT.
Hay cuatros aspectos a tener en cuenta:
- La privacidad se encarga de que solo los ICOs y gateways debidos formen parte de una red IoT. En este sentido la autenticación de dispositivos y confianza entre ellos es uno de los grandes caballos de batalla. Por ejemplo, todas las aplicaciones que conllevan transmisión de datos personales (estado de salud, ubicación, hábitos de vida, etc) deben estar especialmente vigiladas, no solamente haciendo que la información no salga de la «red», sino incluso que solo ciertos nodos sean los autorizados a acceder a la misma, como verás más adelante en la «confidencialidad».
- La autenticidad hace referencia a la confianza en el dato y en la legitimidad de quien lo está enviando. No es un tema menor, toda una infraestructura crítica podría verse comprometida simplemente aceptando datos falsos de sensores no autorizados, simulando así una situación que no es la real.
- La confidencialidad puede llegar a ser un aspecto clave en ciertas aplicaciones. Se trata de que solamente quien tiene que recibir el dato sea capaz de leerlo, y ningún otro elemento de la red pueda acceder al mismo. Hoy en día existen técnicas que de sobra nos dan esta funcionalidad, pero el problema que encuentra IoT es que todas ellas hay que implementarlas en dispositivos con poca capacidad de procesamiento.
- Y por último, la integridad del dato persigue que éste permanezca invariable durante toda la transmisión, que el mismo dato enviado es el que se recibe y no sufre ninguna alteración o error durante el camino. Existen algoritmos que son capaces de todo esto y más, pero es necesario que exista una coordinación entre emisor y receptor y un acuerdo de cómo se va a enviar la información. En un entorno dinámico como el que estamos describiendo, esto no es trivial.
Es muy posible que estas soluciones no sean únicas para todas las comunicaciones posibles en un entorno de fog computing. Claramente se ven que las siguientes situaciones no podrán tener las mismas características de seguridad:
- Comunicación entre ICOs: En estas comunicaciones trataremos de evitar que los ICOs que no pertenezcan a nuestra red o nuestro grupo puedan acceder a las comunicaciones. O evitar que un nodo malicioso capte información. Para evitarlo lo típico es usar encriptación simétrica entre emisor y receptor (normalmente AES128), usando para ello una clave compartida, probablemente la misma para un grupo completo de nodos para comunicarse entre ellos
- Comunicación de ICO a Gateway: La comunicación con el gateway sí que puede ser algo diferente, usando para ello una clave privada por cada ICO. Los gateways de destino deben tener las claves de cada ICO para poder desencriptar el mensaje. Sin embargo, al mismo tiempo, los nodos de salto intermedios no debe poder acceder al mensaje, si es que es un requisito de la aplicación concreta. AES256 es la técnica usada más comunmente.
- Comunicación de ICO a Cloud: ES una ampliación del caso anterior: en las ocasiones donde el ICO deba comunicarse directamente con la nube se pueden seguir los mismos patrones de encriptación simétrica. Pero la aplicación en la nube debe poder tener acceso a las claves de desencriptación de los ICOs.
- Comunicación de Gateway a Cloud: Lo más típico es usar HTTPS (HTTP sobre SSL/TLS) para encriptar la comunicación con la nube, pues la aplicación de destino suele tratarse de un servidor web estándar.
- Comunicación de Cloud a ICO o Gateway: Suelen producirse sobre todo al inicio de las comunicaciones entre los elementos de la red. La solución a usar es normalmente los sitemas de clave pública.
Integración con la nube
Y, finalmente, ¿qué hacemos con la nube? Hemos hablado de la nube como si fuera un solo objeto, pero basta que le dediques unos minutos a buscar plataformas IoT en la nube para que veas la cantidad de empresas que te ofrecen este tipo de servicios, más allá de los típicos de Microsoft, Amazon o Google.
Pensemos un momento: vamos a desplegar un sistema IoT o una arquitectura Fog Computing por cada proveedor de Cloud que tengamos? No, verdad? Por lo tanto nuestro sistema Fog debe ser capaz de comunicarse con todas las aplicaciones en las «distintas nubes» que lo requieran, manteniendo las funcionalidades y características que hemos ido desgranando a lo largo de este post.
De nuevo la palabra interoperabilidad se vuelve necesaria, y la integración multi-cloud, el intercambio de datos entre aplicaciones y la aplicación de estándares serán necesarios.
Y hasta aquí este artículo sobre fog computing. Espero sinceramente que te haya gustado y disfrutes con este tipo de contenidos.
Puedes usar el formulario de contacto para proponer temas nuevos, o los comentarios si quieres añadir algo a lo expuesto.
Te aconsejo que sigas la cuenta @iotfutura en twitter y te suscribas al blog. No se envía ni publicidad ni nada por el estilo, solo los post nuevos que aparecen en esta página. La cuenta de twitter suele estar activa casi todos los días y comparte siempre contenido tecnológico interesante.
Te agradezo tu atención, nos leemos en el próximo !
Have you ever considered publishing an ebook or guest authoring on other sites?
I have a blog based upon on the same ideas you discuss and would really like to have you share some stories/information. I know my visitors would value your
work. If you’re even remotely interested, feel free
to shoot me an email.
Thanks for your offering, I really apreciate it. Unfortunately I am in a busy moment and cannot attend other hobbies, like writing my own blog. But I will consider your choice if I find more spare time in the future. Good day !